01_Introduction
Lernmaterialien
Neo4j
Neo4j is a graph database—a database designed to store and query data as a network of nodes (things) and relationships (connections between things), both of which can have properties (key–value data).
How it models data
Node: an entity (e.g.,
Person,Company,Movie)Relationship: a typed, directed connection (e.g.,
(:Person)-[:FRIENDS_WITH]->(:Person))Properties: data on nodes/relationships (e.g.,
name,age,since)
This is often called the property graph model.
How you query it
Neo4j’s main query language is Cypher, which looks a bit like ASCII-art patterns:
MATCH (p:Person {name: "Alice"})-[:FRIENDS_WITH]->(f:Person)
RETURN f.nameThat reads: “Find Alice, follow her FRIENDS_WITH
relationships to other Person nodes, return their
names.”
Why use Neo4j
Neo4j is especially good when your main questions are about connections:
social networks (“friends of friends”)
recommendations (“people who bought X also bought Y”)
fraud detection (suspicious rings of accounts/devices)
knowledge graphs and entity linking
network/IT topology and dependency analysis
Graph databases shine because they can traverse relationships efficiently without lots of costly joins.
How it differs from relational databases
Relational: relationships are implied via foreign keys + joins
Neo4j: relationships are first-class stored data, so multi-hop queries can be simpler and often faster.
If you tell me what kind of data/problem you’re working with (e.g., students/courses, products/users, etc.), I can sketch what the Neo4j graph model would look like and show a few example Cypher queries.
Differences
Neo4j vs Relational (Oracle/Postgres/MySQL)
Data model
Relational: tables + rows; relationships via foreign keys.
Neo4j: nodes + relationships (stored directly) + properties.
Query style
Relational: set-based SQL; relationships expressed with JOINs.
Neo4j: pattern matching (“find this shape in the graph”) in Cypher.
Strengths
Relational excels at: well-structured data, reporting/aggregations, lots of tabular operations, strong integrity constraints.
Neo4j excels at: “connected” questions (multi-hop traversals): friends-of-friends, shortest paths, dependency chains, recommendations, fraud rings.
Performance “shape”
Relational: queries that need many joins (especially variable-depth like 2–6 hops, unknown depth) can get complex and expensive.
Neo4j: traversals over relationships are typically efficient, and variable-length path queries are natural.
Integrity & normalization
Relational: normalization is common; constraints (FK, CHECK, UNIQUE) are core.
Neo4j: you can add constraints (e.g., uniqueness), but graph modeling often emphasizes relationships over normalization.
Neo4j vs MongoDB (document DB)
Data model
MongoDB: documents (JSON-like) in collections; nested objects/arrays; relationships often handled by embedding or references.
Neo4j: explicit relationships as first-class records; good when links are central.
How you represent relationships
MongoDB embedding: fast when you usually fetch data “with its children” (e.g., an order with its line items).
MongoDB referencing: possible, but multi-step traversals become multiple queries or aggregation pipelines.
Neo4j: traversals are the core operation—follow edges naturally across many hops.
Querying
MongoDB: document queries + aggregation pipeline (great for document-shaped analytics).
Neo4j: Cypher pattern queries (great for network/graph patterns).
Performance “shape”
MongoDB: great for single-entity reads/writes and “retrieve a document and its embedded data” patterns.
Neo4j: great for deep or wide relationship navigation and graph algorithms (paths, centrality, communities).
Schema flexibility
MongoDB: very flexible schema per document.
Neo4j: also flexible (properties/labels can vary), but the shape of relationships matters more than document structure.
Quick rule of thumb
Choose a relational DB when your world is naturally tables, you need strong constraints, and most queries are joins/aggregations over well-defined entities.
Choose MongoDB when your data is naturally document-shaped, you want easy horizontal scaling, and you mostly fetch/update whole documents.
Choose Neo4j when your hardest/most valuable questions are about connections, paths, and network structure.
Tiny example: “friends of friends”
SQL: self-joins, potentially multiple joins for multiple hops.
MongoDB: usually multiple lookups/aggregation stages or app-side joins.
Neo4j (Cypher):
MATCH (a)-[:FRIEND*2]->(b)(variable-length is natural).
Components
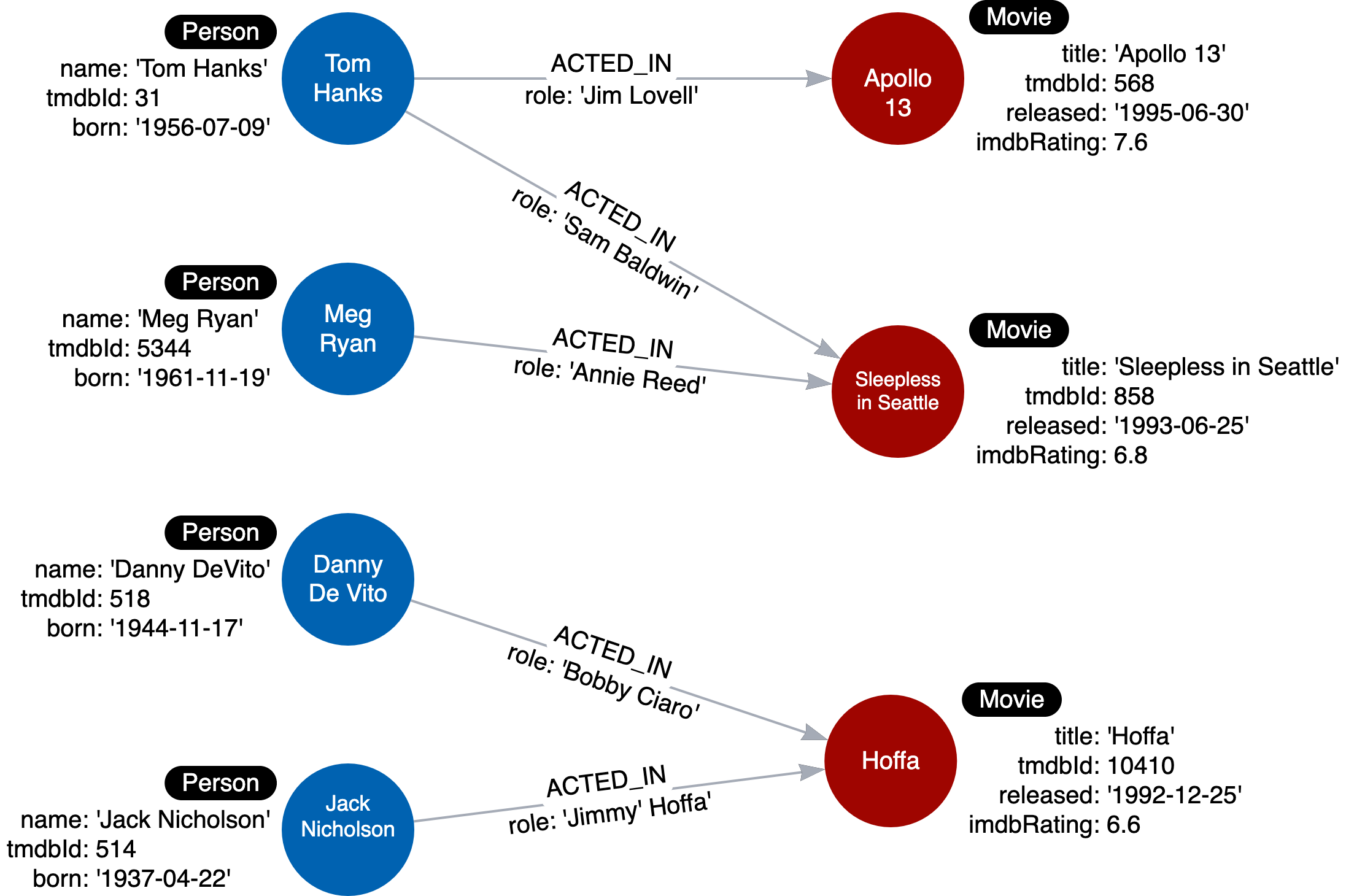
https://graphacademy.neo4j.com/courses/modeling-fundamentals/1-getting-started/3-purpose-of-model/
Main components:
Nodes (entities)
Blue nodes: people (e.g., Tom Hanks, Meg Ryan)
Red nodes: movies (e.g., Apollo 13, Sleepless in Seattle)
Labels (node types / classes)
:Personand:Movie(shown in the black “Person/Movie” tags)
Properties (attributes on nodes)
For
:Person:name,tmdbId,bornFor
:Movie:title,tmdbId,released,imdbRating
Relationships (connections / edges)
- Type:
:ACTED_INconnecting(:Person) -> (:Movie)(direction matters)
- Type:
Relationship properties (attributes on relationships)
role(e.g., “Jim Lovell”, “Annie Reed”) stored on theACTED_INrelationship
Nodes
Nodes are the “things” (entities) in a Neo4j graph. Each node represents one real-world object or concept—like a Person or a Movie in your diagram.
How to recognize a node
A node is identified by:
Labels (type/category)
Example::Person,:MovieProperties (key–value fields)
Example:name,born,title,releasedAn internal Neo4j id (exists, but you usually don’t rely on it in app design)
How to identify (find) nodes in practice
1) By label + property (most common)
MATCH (p:Person {name: "Tom Hanks"})
RETURN p2) By a unique identifier property (best practice)
Use something like tmdbId as a stable ID:
MATCH (m:Movie {tmdbId: 568})
RETURN mEven better: enforce uniqueness with a constraint:
CREATE CONSTRAINT person_tmdbId_unique IF NOT EXISTS
FOR (p:Person) REQUIRE p.tmdbId IS UNIQUE;3) By internal id (ok for debugging, not for long-term use)
MATCH (n) WHERE id(n) = 123
RETURN nIn the diagram
The circles are nodes:
Blue circles (Tom Hanks, Meg Ryan, …) are
:PersonnodesRed circles (Apollo 13, …) are
:Movienodes
If you tell me what dataset you’re using (movies, students/courses, etc.), I can suggest what property should be your “unique ID” and the right constraints to add.
Relationships
Relationships are the connections
(edges) between two nodes in Neo4j. They’re
typed (have a name like ACTED_IN),
directed (have a start and end node), and can also hold
properties (like role).
In your diagram:
(Tom Hanks)-[:ACTED_IN {role:"Jim Lovell"}]->(Apollo 13)(Meg Ryan)-[:ACTED_IN {role:"Annie Reed"}]->(Sleepless in Seattle)
What makes up a relationship
Type: the relationship name, e.g.
:ACTED_INDirection: from start node → end node
Properties: key–value data on the relationship, e.g.
roleInternal relationship id (exists, mainly for debugging)
How to identify (find) relationships
1) By pattern (most common)
Find all acting relationships for Tom Hanks:
MATCH (:Person {name:"Tom Hanks"})-[r:ACTED_IN]->(m:Movie)
RETURN r, m2) By relationship properties
Find acting relationships where the role is “Jim Lovell”:
MATCH (p:Person)-[r:ACTED_IN {role:"Jim Lovell"}]->(m:Movie)
RETURN p, m3) By start/end node + type
Find the relationship specifically between Tom Hanks and Apollo 13:
MATCH (:Person {name:"Tom Hanks"})-[r:ACTED_IN]->(:Movie {title:"Apollo 13"})
RETURN r4) By internal relationship id (debugging)
MATCH ()-[r]->() WHERE id(r) = 42
RETURN rTips / best practice
Identify relationships in apps by (start node, type, end node) and/or relationship properties.
Unlike nodes, relationships typically don’t have a “natural primary key” unless you model one yourself.
You can add constraints/indexes for relationship properties in newer Neo4j versions, but most of the time you query them via the surrounding pattern.